BigQuery is made to process massive amounts of data efficiently, but quite often I hear of people having trouble with high cost queries and/or slow running queries.
This is usually related to the way these queries have been written, because BigQuery optimization is different than optimizing a common relational database like Postgres or MySQL. To identify and eliminate BigQuery bottlenecks you need to understand how BigQuery billing works, and how queries are processed. Put another way, if you want to make things faster and reduce your bills, you need to understand what is slow, and what’s costing you the most.
BigQuery Pricing
BigQuery pricing is based on storage and compute resources used for querying. You pay a small monthly fee for storing your data (around $0.02 per GB), which is pretty cheap even for large datasets. The real costs come from running queries, where you’re charged based on how much data your queries scan through, not how long they take to run.
The compute pricing works on a “pay per query” model where you’re billed roughly $5 for every terabyte of data that gets processed. This means a query that scans 100 GB costs about $0.50, while a poorly optimized query that scans 10 TB costs $50. The tricky part is that BigQuery charges for all the data it has to look at to answer your question, even if your final results are tiny. This is why query optimization is critical, it can save thousands of dollars per month by reducing the amount of data each query needs to scan and therefor reducing compute usage.
Fundamental Differences of BigQuery
 BigQuery operates fundamentally differently from MySQL/PostgreSQL because it’s designed for massive datasets and analytical workloads rather than transactional operations. Where MySQL optimizes for fast row-by-row operations and PostgreSQL excels at complex joins on smaller datasets, BigQuery is built to scan billions of rows incredibly fast using parallel processing across thousands of machines.
BigQuery operates fundamentally differently from MySQL/PostgreSQL because it’s designed for massive datasets and analytical workloads rather than transactional operations. Where MySQL optimizes for fast row-by-row operations and PostgreSQL excels at complex joins on smaller datasets, BigQuery is built to scan billions of rows incredibly fast using parallel processing across thousands of machines.
The key difference is that BigQuery stores data in a columnar format and charges you based on how much data it scans, not execution time. In MySQL/PostgreSQL, you optimize for speed using indexes, but in BigQuery you optimize for cost by reducing data scanning through partitioning and clustering. A poorly written BigQuery query might scan 10 TB and cost $50, while the same query optimized with proper partitioning might scan 10 GB and cost $0.05. There’s no equivalent to traditional indexes, instead you use partition pruning and clustering to eliminate entire chunks of data from consideration. This means query patterns that work well in relational databases (like complex WHERE clauses without partition filters) can be extremely expensive in BigQuery, while operations that would be slow in MySQL/PostgreSQL (like scanning millions of rows for aggregations) are lightning fast and cheap when done correctly.
Query Execution Analysis
The first step in identifying bottlenecks involves examining query execution details through BigQuery’s built-in monitoring tools. We can access comprehensive performance metrics that reveal exactly where queries are spending time and resources.
BigQuery provides detailed execution statistics for every query through the console interface. Navigate to the Job History section and select any completed query to view its execution details. The most critical metrics include elapsed time, slot time consumed, bytes processed, and bytes shuffled.
Slot time represents the actual compute resources consumed by your query. When slot time significantly exceeds elapsed time, it indicates your query is using parallel processing effectively. However, when these numbers are nearly identical, your query likely has serialization bottlenecks that prevent parallel execution.
SQL
SELECT
job_id,
user_email,
TIMESTAMP_DIFF(end_time, start_time, MILLISECOND) as job_time_ms,
query,
ROUND(total_bytes_processed / 1024 / 1024 / 1024, 3) as total_gb_processed,
ROUND(total_bytes_billed / 1024 / 1024 / 1024, 3) as total_gb_billed,
FORMAT("$%.2f", (total_bytes_billed / 1024 / 1024 / 1024 / 1024) * 6.25) as estimated_cost_usd,
total_slot_ms,
creation_time
FROM `region-us`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
WHERE job_type = "QUERY"
AND state = "DONE"
AND creation_time >= TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 7 DAY)
ORDER BY total_bytes_processed DESC
LIMIT 50;
Output
This query provides output like this:
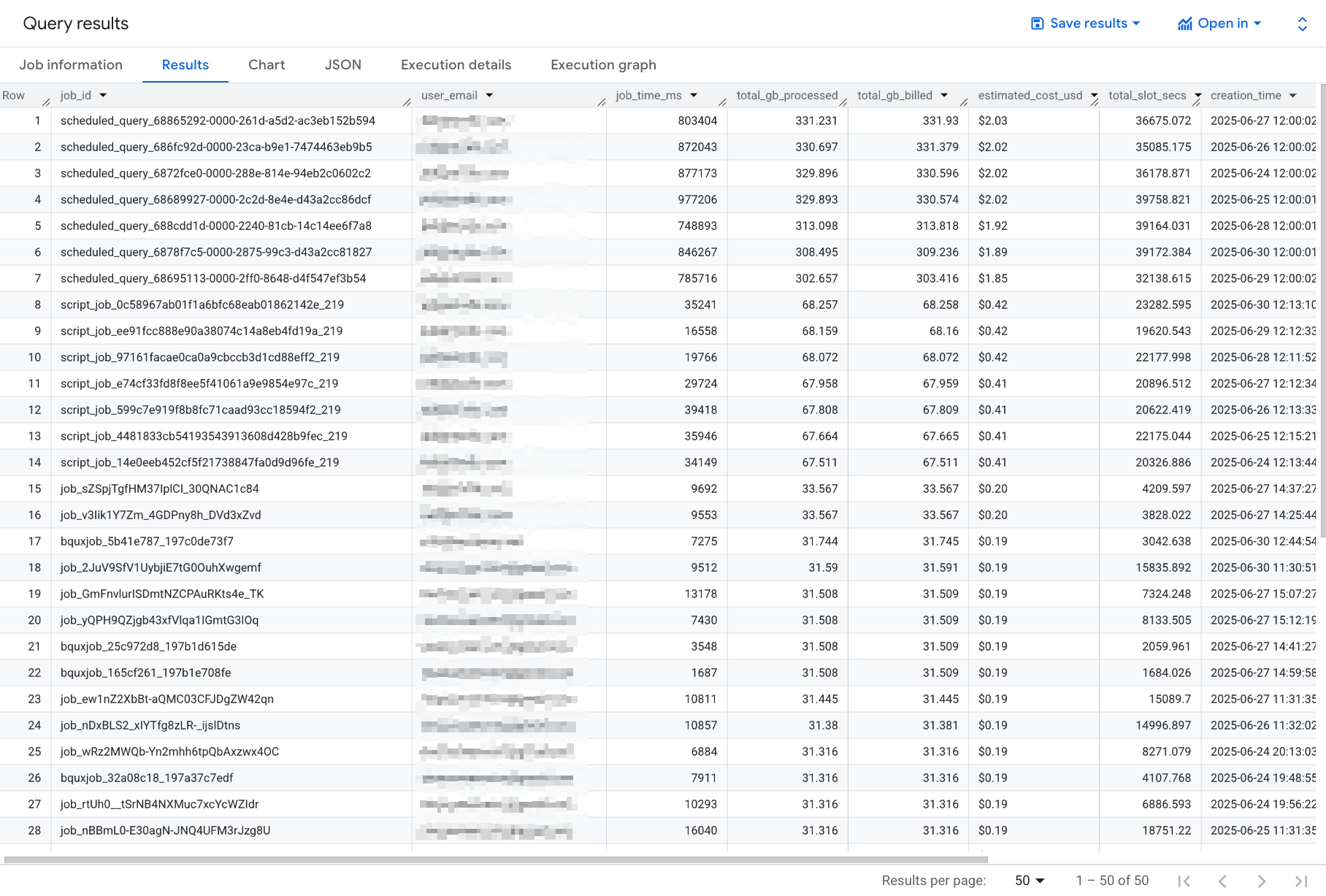
Table Partitioning Issues
Poorly partitioned tables are the most common cause of expensive queries that scan unnecessary data. BigQuery performs best when queries can eliminate entire partitions from consideration, but this only happens when partition columns are used effectively in WHERE clauses.
We can identify partition pruning problems by examining the bytes processed versus bytes billed metrics. When these numbers differ significantly, BigQuery is scanning more data than necessary due to ineffective partition filtering.
Check your most expensive queries to see if they’re filtering on partition columns. Queries that scan entire tables without partition filters are red flags that indicate immediate optimization opportunities. The partition column should appear in every query’s WHERE clause to ensure efficient data access.
-- Check partition pruning effectiveness
SELECT
table_name,
partition_id,
total_rows,
total_logical_bytes
FROM `project.dataset.INFORMATION_SCHEMA.PARTITIONS`
WHERE table_name = 'your_table_name'
AND partition_id IS NOT NULL
ORDER BY total_logical_bytes DESC;
Clustering Analysis
Table clustering works alongside partitioning to further optimize query performance. Clustered tables store data in sorted order based on specified columns, which allows BigQuery to skip irrelevant data blocks during query execution.
We can evaluate clustering effectiveness by monitoring the bytes shuffled metric. High shuffle operations indicate that data is being moved across slots during query execution, which often happens when queries don’t align with clustering columns.
Review your query patterns to ensure clustering columns match your most common filter and join conditions. Misaligned clustering can actually hurt performance by forcing unnecessary data reorganization during query execution.
Slot Utilization Problems
BigQuery allocates computational resources called slots to execute queries. Slot contention occurs when multiple queries compete for limited slot capacity, causing queries to queue and wait for available resources. This directly impacts Looker performance when dashboards attempt to refresh data during peak usage periods.
We can identify slot bottlenecks by examining query queuing times in the execution details. Queries that spend significant time in pending status before execution indicate slot capacity issues that require attention. Looker Studio reports and Looker dashboards are particularly sensitive to slot availability since users expect near-instant data refreshes.
Monitor your project’s slot usage patterns throughout the day to identify peak usage periods. Queries executed during high-demand periods will experience longer queue times and reduced performance compared to off-peak execution. Schedule intensive Looker data refreshes during off-peak hours to avoid slot contention with interactive queries.
-- Monitor slot usage over time
SELECT
EXTRACT(HOUR FROM creation_time) as hour,
COUNT(*) as query_count,
AVG(total_slot_ms) as avg_slot_time,
MAX(total_slot_ms) as max_slot_time
FROM `region-us`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
WHERE creation_time >= TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 7 DAY)
AND job_type = 'QUERY'
GROUP BY hour
ORDER BY hour;
Reserved vs On-Demand Slots
Organizations with predictable query patterns benefit from reserved slot capacity, which provides guaranteed computational resources at lower costs. On-demand slots work well for sporadic workloads but can become expensive with consistent heavy usage from Looker dashboards and automated reports.
Analyze your slot consumption patterns to determine if reserved capacity makes financial sense. Projects that consistently use more than 500 slots should evaluate reserved pricing models for potential cost savings. Looker environments with multiple concurrent users and frequent dashboard refreshes typically justify reserved slot investments.
Query Structure Optimization
Inefficient SQL patterns are major contributors to poor BigQuery performance. Common anti-patterns include unnecessary subqueries, improper join orders, and missing aggregation optimizations.
We can identify problematic query structures by examining the query execution graph in BigQuery’s console. Look for stages that process significantly more data than subsequent stages, which indicates inefficient filtering or aggregation logic.
Cross joins and cartesian products are particularly expensive operations that should be avoided. These operations multiply row counts exponentially and can quickly consume massive slot resources without producing meaningful results.
-- Example of optimized vs unoptimized query patterns
-- AVOID: Filtering after joins
SELECT *
FROM table_a a
JOIN table_b b ON a.id = b.id
WHERE a.created_date >= '2024-01-01';
-- PREFER: Filter before joins
SELECT *
FROM (
SELECT * FROM table_a
WHERE created_date >= '2024-01-01'
) a
JOIN table_b b ON a.id = b.id;
Window Function Performance
Window functions can create performance bottlenecks when used inefficiently. Large partition sizes force BigQuery to sort and process massive data sets within individual partitions, leading to memory pressure and slow execution.
Review window function usage to ensure partitions are appropriately sized. Partitions containing millions of rows should be subdivided using additional partition columns or alternative query approaches.
Storage Layout Impact
BigQuery’s columnar storage format performs best when queries access only necessary columns. SELECT * queries force BigQuery to read entire tables even when only specific columns are needed for results.
We can identify storage inefficiencies by comparing bytes processed against the actual data requirements. Queries that process significantly more data than their output suggests are likely reading unnecessary columns or rows.
Examine your table schemas to identify unused or rarely accessed columns. Large tables with wide schemas benefit from column pruning or restructuring to improve query performance across all access patterns.
Monitoring and Alerting
Establishing systematic monitoring helps identify performance degradation before it impacts business operations. BigQuery provides comprehensive logging through Cloud Logging that captures detailed query execution metrics. This becomes critical when supporting Looker Studio reports and Looker dashboards that users depend on for daily operations.
We can create alerts based on query execution time, slot consumption, or bytes processed thresholds. Automated monitoring catches performance regressions early and enables proactive optimization efforts. Set specific alerts for Looker query performance to ensure dashboard users maintain acceptable response times.
Set up dashboards that track key performance indicators including average query time, slot utilization, and cost per query. These metrics provide visibility into data warehouse health and help justify optimization investments. Monitor Looker-generated queries separately to understand their specific impact on overall system performance.
-- Create performance monitoring query
SELECT
DATE(creation_time) as query_date,
AVG(total_slot_ms / 1000) as avg_slot_seconds,
AVG(total_bytes_processed / 1024 / 1024 / 1024) as avg_gb_processed,
COUNT(*) as total_queries
FROM `region-us`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
WHERE creation_time >= TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 30 DAY)
AND job_type = 'QUERY'
GROUP BY query_date
ORDER BY query_date DESC;
Conclusion
BigQuery performance bottlenecks stem from predictable sources including poor partitioning strategies, inefficient query patterns, and inadequate resource allocation. Systematic analysis of query execution metrics reveals optimization opportunities that significantly improve performance and reduce costs. These optimizations become even more valuable when supporting Looker environments where multiple users expect fast dashboard performance.
The most impactful optimizations focus on partition pruning, clustering alignment, and query structure improvements. These changes often provide 10x or greater performance improvements while reducing computational costs proportionally. Looker Studio and Looker dashboard performance benefits directly from these BigQuery optimizations.
Regular monitoring and proactive optimization prevent performance degradation and ensure your data warehouse scales effectively with growing business requirements. Investing time in proper BigQuery optimization pays dividends through faster insights and lower operational expenses, especially in Looker deployments where query costs can escalate quickly with user adoption.